Azure HDInsight est un service Apache Hadoop managé, complet et open source pour les entreprises. Il permet d'exécuter, entre autres, Apache Spark, Apache Hive, Apache Kafka et Apache HBase dans le cloud.
Il rend facile, rapide et économique le traitement de volumes importants de données.
Pour plus d'informations sur ce service : https://docs.microsoft.com/fr-fr/azure/hdinsight/hdinsight-overview
Il peut cependant arriver que nous n'ayons pas besoin d'avoir un cluster Hadoop disponible à tout moment, mais plutôt pour des tâches spécifiques à des instants donnés.
Pour l'optimisation des coûts, le cluster peut être supprimé et recréé à la demande.
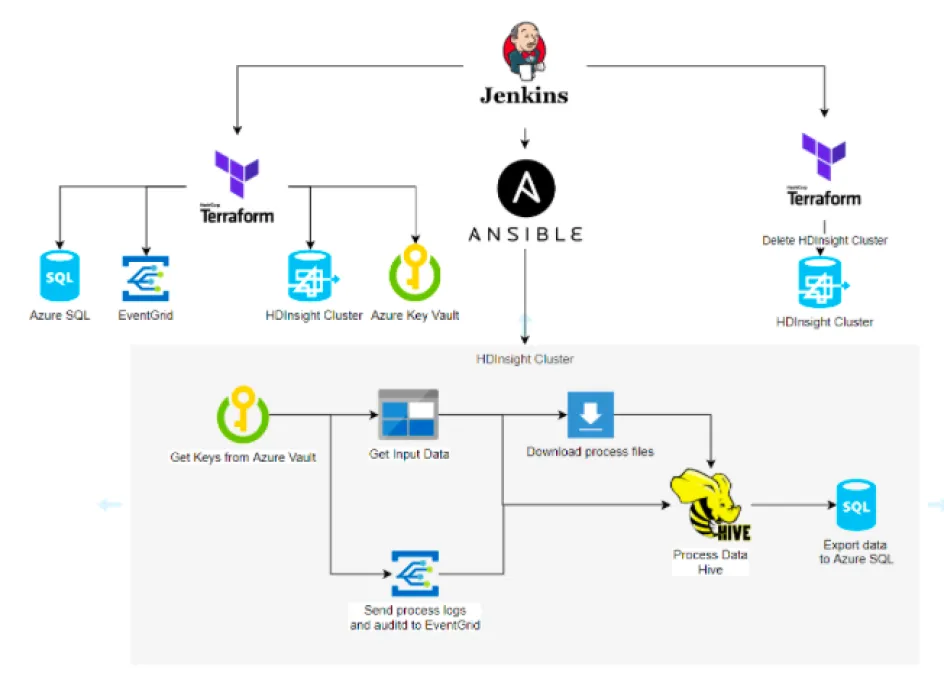
L'objectif de ce tutoriel est donc de décrire comment mettre en place un process de déploiement à la demande d'HDInsight.
Les outils que nous utiliserons :
- Jenkins (pour l'orchestration des taches de déploiement, de process et de suppression du cluster)
- Terraform pour le déploiement et la suppression des ressources dans Azure
Les actions que nous allons parcourir dans ce tutoriel:
- Téléchargement des données d'input
- Création des scripts de traitement de données
- Création des ressources via Terraform
- Création du process d’exécution dans Ansible
- Création des tâches dans Jenkins
Prérequis
- Une souscription Azure
- Un service principal avec des droits de création dans Azure
- Un compte de stockage dans Azure (pour les données en Input)
- Un serveur base de données Azure SQL. Si elle n'est pas existante, il sera créé dans ce tutoriel.
- Un environnement Terraform
- Un environnement Ansible
- Un environnement Jenkins
- Des scripts de traitement de données.
Schéma du process
Modernisez vos plateformes Data
Téléchargement du jeux de données
Vous pouvez vous référer à cet article pour le chargement du jeux de données (https://docs.microsoft.com/en-us/azure/hdinsight/interactive-query/inter...)
Création des ressources - Terraform
Pour exécuter votre script Terraform, créez une shell action dans Jenkins qui exécute cette commande:
cd /var/lib/terraform/azu-bigdata-hdinsight
terraform apply --auto-approve
|
EventGrid
resource "azurerm_eventgrid_topic" "eventgridtopic" {
name = "bigdata202005-topic"
resource_group_name = "${var.hdi_rg}"
location = "${var.hdi_location}"
}
|
resource "azurerm_storage_queue" "sqbigdata" {
name = "egsasq"
resource_group_name = "${var.hdi_rg}"
storage_account_name = "${azurerm_storage_account.egsabigdata.name}"
}
|
- Une EventGrid subscription avec un Storage Queue Endpoint
data "azurerm_resource_group" "sqrg" {
name = "${var.hdi_rg}"
}
resource "azurerm_eventgrid_event_subscription" "egsubscription" {
name = "egsubscription"
scope = "${azurerm_eventgrid_topic.eventgridtopic.id}"
storage_queue_endpoint {
storage_account_id = "${azurerm_storage_account.egsabigdata.id}"
queue_name = "${azurerm_storage_queue.sqbigdata.name}"
}
}
|
HDInsight
- Un compte de stockage et un container qui serviront de montage HDFS sur le cluster
resource "azurerm_storage_account" "hdisa" {
name = "${var.hdi_storage_account}"
resource_group_name = "${var.hdi_rg_result}"
location = "${var.hdi_location}"
account_tier = "Standard"
account_replication_type = "LRS"
}
resource "azurerm_storage_container" "hdicont" {
name = "hdi-cont"
storage_account_name = "${azurerm_storage_account.hdisa.name}"
container_access_type = "private"
resource_group_name = "${var.hdi_rg_result}"
}
|
resource "azurerm_hdinsight_hadoop_cluster" "hdicluster" {
name = "hdi-cluster-202005"
resource_group_name = "${var.hdi_rg}"
location = "${var.hdi_location}"
cluster_version = "3.6"
tier = "Standard"
component_version {
hadoop = "2.7"
}
gateway {
enabled = true
username = "claranet"
password = "${var.passwd}"
}
storage_account {
storage_container_id = "${azurerm_storage_container.hdicont.id}"
storage_account_key = "${azurerm_storage_account.hdisa.primary_access_key}"
is_default = true
}
roles {
head_node {
vm_size = "Standard_D3_V2"
username = "claranet"
password = "${var.passwd}"
}
worker_node {
vm_size = "Standard_D4_V2"
username = "claranet"
password = "${var.passwd}"
target_instance_count = 1
}
zookeeper_node {
vm_size = "Standard_D3_V2"
username = "claranet"
password = "${var.passwd}"
}
}
}
|
Modernisez vos plateformes Data
data "external" "hdiip" {
depends_on = ["azurerm_hdinsight_hadoop_cluster.hdicluster"]
program = ["sh","./resolve.sh"]
}
resource "local_file" "inventory" {
content = "hdinsight ansible_host=${lookup(data.external.hdiip.result, "ip")}"
filename = "/tmp/hdinsight-inventory.ini"
}
|
- Un fichier d'inventaire pour Jenkins.
Ce fichier contient l’adresse IP du Cluster. Il nous permettra d'exécuter les commandes Ansible
data "azurerm_storage_account_sas" "hdissas" {
connection_string = "${azurerm_storage_account.hdisa.primary_connection_string}"
https_only = true
resource_types {
service = true
container = true
object = true
}
services {
blob = true
queue = true
table = true
file = true
}
start = "2020-01-20"
expiry = "2021-03-21"
permissions {
read = true
write = true
delete = true
list = true
add = true
create = true
update = true
process = true
}
}
resource "local_file" "inventory" {
content = "hdinsight ansible_host=${lookup(data.external.hdiip.result, "ip")}"
filename = "/tmp/hdinsight-inventory.ini"
}
|
Azure SQL
resource "azurerm_sql_server" "hdiserver" {
name = "hdiserver202005"
location = "${var.hdi_location}"
resource_group_name = "${var.hdi_rg}"
version = "12.0"
administrator_login = "claranet"
administrator_login_password = "${var.passwd}"
}
|
- Une base de données SQL et une table pour la mise à disposition des outputs (si elles n'existent pas déjà)
resource "azurerm_sql_database" "hdidb" {
name = "hdidb"
location = "${var.hdi_location}"
resource_group_name = "${var.hdi_rg}"
server_name = "${azurerm_sql_server.hdiserver.name}"
}
|
- Une règle firewall dans Azure SQL pour permettre au Cluster de s'y connecter
resource "azurerm_sql_firewall_rule" "hdifw" {
name = "hdifw"
resource_group_name = "${var.hdi_rg}"
server_name = "${azurerm_sql_server.hdiserver.name}"
start_ip_address = "${lookup(data.external.hdiip.result, "ip")}"
end_ip_address = "${lookup(data.external.hdiip.result, "ip")}"
}
|
Azure Keyvault
- Un Azure Keyvault (pour le stockage de diverses informations)
resource "azurerm_key_vault" "hdikeyvault" {
# name = "${format("%s%s", "kv", random_id.server.hex)}"
name = "hdikeyvault202005"
location = "${var.location}"
resource_group_name = "${var.rg}"
tenant_id = "${var.tenant_id}"
sku_name = "standard"
access_policy {
tenant_id = "${var.tenant_id}"
object_id = "${var.object_id}"
key_permissions = [
"create",
"get",
]
secret_permissions = [
"set",
"get",
"delete",
]
}
}
|
- Tokens générés pour les comptes de stockage
resource "azurerm_key_vault_secret" "sastoken" {
name = "sastoken"
value = "${replace(data.azurerm_storage_account_sas.hdissas.sas,"?", "")}"
key_vault_id = "${azurerm_key_vault.hdikeyvault.id}"
}
|
- Credentials pour l'accès aux bases de données
resource "azurerm_key_vault_secret" "sqlpassword" {
name = "sqlpassword"
value = "${var.passwd}"
key_vault_id = "${azurerm_key_vault.hdikeyvault.id}"
}
resource "azurerm_key_vault_secret" "userpassword" {
name = "userpassword"
value = "${var.passwd}"
key_vault_id = "${azurerm_key_vault.hdikeyvault.id}"
}
resource "azurerm_key_vault_secret" "masterpassword" {
name = "masterpassword"
value = "${var.passwd}"
key_vault_id = "${azurerm_key_vault.hdikeyvault.id}"
}
|
- Primary acces key pour l'EventGrid Topic
resource "azurerm_key_vault_secret" "hditopic" {
name = "hditopic"
value = "${azurerm_eventgrid_topic.eventgridtopic.primary_access_key}"
key_vault_id = "${azurerm_key_vault.hdikeyvault.id}"
}
|
Traitement des données - Script ansible
- Définition des variables à partir du Keyvault
- name: Get sastoken Key Vault
local_action: command az keyvault secret show --vault-name hdikeyvault202005 --name sastoken --query value --output tsv
register: sastoken
become: false
- name: Get sqlpassword Key Vault
local_action: command az keyvault secret show --vault-name hdikeyvault202005 --name sqlpassword --query value --output tsv
register: sqlpassword
become: false
- name: Get hditopic Key Vault
local_action: command az keyvault secret show --vault-name hdikeyvault202005 --name hditopic --query value --output tsv
register: hditopic
become: false
- name: Get userpassword Key Vault
local_action: command az keyvault secret show --vault-name hdikeyvault202005 --name userpassword --query value --output tsv
register: userpassword
become: false
- name: Get masterpassword Key Vault
local_action: command az keyvault secret show --vault-name hdikeyvault202005 --name masterpassword --query value --output tsv
register: masterpassword
become: false
- set_fact:
SAS_TOKEN: "{{ sastoken.stdout }}"
SQLPASSWORD: "{{ sqlpassword.stdout }}"
MASTER_PASSWORD: "{{ masterpassword.stdout }}"
PASSWORD: "{{ userpassword.stdout }}"
TOPIC_KEY: "{{ hditopic.stdout }}"
become: false
```
- Configuration d'auditd pour les logs de sessions et de connexions
```
- name: Install required packages
package: name="{{item}}" state=present
with_items:
- auditd
- audispd-plugins
become: true
- name: configure auditd
template:
dest: "/etc/audit/rules.d/audit.rules"
src: files/audit.rules
owner: root
group: root
mode: 0600
become: true
- name: Configure audisp
lineinfile:
dest: /etc/audisp/plugins.d/syslog.conf
regexp: '^(.*)active = no(.*)$'
line: 'active = yes'
backrefs: yes
become: true
- name: restart auditd
shell: service auditd restart
become: true
- name: Copy file to remote server
copy:
src: "./files/"
dest: "~/"
# with_items: ['external_datasource.sql', 'cleanupResources.sql', 'tail.py', '']
- name: Copy file to remote server
template:
src: ./templates/{{item}}.j2
dest: "~/{{item}}"
with_items: ['external_datasource.sql', 'cleanupResources.sql', 'tail.py']
- name: Install pipenv
shell: pip install pipenv
become: true
|
Modernisez vos plateformes Data
- Envoi des logs vers l'EventGrid
- name: create process logger
shell: touch process.log
- name: Start auditd logger
shell: cd /home/claranet; pipenv install; nohup pipenv run python tail.py /var/log/audit/audit.log 'auditd' 'auditd' 30 </dev/null >/dev/null 2>&1 &
tags: ['tail']
become: true
- name: Start process logger
shell: cd /home/claranet; pipenv install; nohup pipenv run python tail.py process.log 'process' 'process' 10 </dev/null >/dev/null 2>&1 &
tags: ['tail']
become: true
|
- Téléchargement des fichiers d'Input
- name: set default eula accept policies
shell: sudo debconf-set-selections <<< 'mssql-tools mssql-tools/accept_eula boolean true' && sudo debconf-set-selections <<< 'msodbcsql17 msodbcsql/accept_eula boolean true' && sudo debconf-set-selections <<< 'msodbcsql17 msodbcsql/ACCEPT_EULA boolean true'
- name: add apt_key
shell: curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add -
tags: ['sqlcmd']
become: true
- name: install add apt-source
shell: curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list > /etc/apt/sources.list.d/mssql-release.list
tags: ['sqlcmd']
become: true
- name: install sqlcmd
shell: sudo apt-get update -y && sudo ACCEPT_EULA=Y apt-get install msodbcsql17 -y && sudo ACCEPT_EULA=Y apt-get install mssql-tools -y
tags: ['sqlcmd']
|
- name: create a directory on HDInsigght storage and then copy the .csv to the dir
shell: hdfs dfs -rm -r -f /inputdata && hdfs dfs -mkdir -p /inputdata && hdfs dfs -put {{FILENAME}}.csv /inputdata/
- name: create hive table
shell: beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f {{FILENAME}}.sql >> process.log 2>&1
- name: create hive output table
shell: beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f output.sql >> process.log 2>&1
|
- Exportation des données vers Azure SQL
- name: set default eula accept policies
shell: sudo debconf-set-selections <<< 'mssql-tools mssql-tools/accept_eula boolean true' && sudo debconf-set-selections <<< 'msodbcsql17 msodbcsql/accept_eula boolean true' && sudo debconf-set-selections <<< 'msodbcsql17 msodbcsql/ACCEPT_EULA boolean true'
- name: add apt_key
shell: curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add -
tags: ['sqlcmd']
become: true
- name: install add apt-source
shell: curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list > /etc/apt/sources.list.d/mssql-release.list
tags: ['sqlcmd']
become: true
- name: install sqlcmd
shell: sudo apt-get update -y && sudo ACCEPT_EULA=Y apt-get install msodbcsql17 -y && sudo ACCEPT_EULA=Y apt-get install mssql-tools -y
tags: ['sqlcmd']
- name: Execute SQL Azure script (Export data from Hive to azure)
shell: /opt/mssql-tools/bin/sqlcmd -S {{SQLSERVERNAME}}.database.windows.net -U {{SQLUSER}} -P {{SQLPASSWORD}} -d {{DATABASE}} -i external_datasource.sql >> process.log 2>&1
|
Suppression du Cluster et des ressources
La suppression des ressources se fera à partir de Terraform.
Pour cela, il suffit d'exécuter ces commandes que nous ajouterons directement dans Jenkins (en Shell action)
Vous pouvez dé-commenter les ressources que vous souhaitez supprimer.
cd /var/lib/terraform/azu-bigdata-hdinsight
## keyvault
terraform destroy -target=azurerm_key_vault.hdikeyvault --auto-approve
## cluster
terraform destroy -target=azurerm_hdinsight_hadoop_cluster.hdicluster --auto-approve
terraform destroy -target=azurerm_storage_container.hdicont --auto-approve
terraform destroy -target=azurerm_storage_account.hdisa --auto-approve
## server
# terraform destroy -target=azurerm_sql_firewall_rule.hdifw --auto-approve
# terraform destroy -target=azurerm_sql_firewall_rule.hdifwclaranet --auto-approve
# terraform destroy -target=azurerm_sql_database.hdidb --auto-approve
# terraform destroy -target=azurerm_sql_server.hdiserver --auto-approve
## eventgrid
#terraform destroy -target=azurerm_eventgrid_event_subscription.egsubscription --auto-approve
# terraform destroy -target=azurerm_storage_queue.sqbigdata --auto-approve
# terraform destroy -target=azurerm_storage_account.egsabigdata --auto-approve
#terraform destroy -target=azurerm_eventgrid_topic.eventgridtopic --auto-approve
|
En résumé
Nos clients nous sollicitent régulièrement pour comprendre comment exécuter des charges de travail à la demande, sans provisionner en permanence des ressources comme HDInsight et Event Grid au sein d’Azure.
Le process décrit ici constitue une réponse DevOps à cette question. Il s’agit de provisionner de façon automatique tout un environnement HDInsight et EventGrid le temps de l’exécution de la charge de travail, et un dé-provisionnement à la fin, le résultat du traitement étant stocké sur un stockage persistant de type blob Azure et une base de données Azure SQL).
Auteur : Phinées NTUMBA, Ingénieur Cloud et DevOps de la Cellule Big Data de Claranet.
Lire aussi : Analyser les changements avec Debezium et Kafka Streams