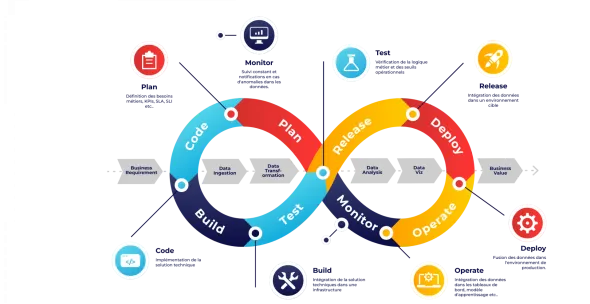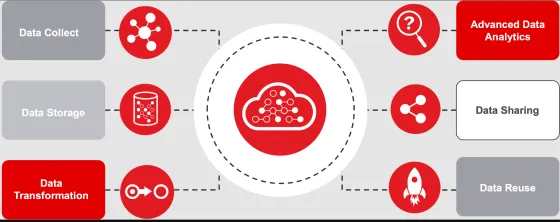
Data Management : comprendre la chaîne de valeur data
La chaîne de valeur des données
La gestion efficace des données est devenue un enjeu crucial pour les organisations. Voici les principales étapes de la chaîne de valeur des données :
Collecte et source des données
La collecte
La collecte des données est une étape fondamentale qui impacte l'ensemble de la chaîne de valeur :
- Aspect réglementaire : La collecte doit se conformer aux obligations légales en matière de données personnelles, notamment le recueil du consentement et la pseudonymisation/anonymisation des données.
- Aspect technique : L'automatisation de la collecte, du transport et de l'intégration des données vers l'entrepôt de données est stratégique. Cela implique :
- L'interconnexion avec les sources de données internes
- La création de liens potentiels avec d'autres entrepôts de données
- L'enrichissement des jeux de données avec des sources externes
- Optimisation du processus : L'objectif est de minimiser les opérations manuelles, résoudre les problèmes de corruption des données et éliminer les goulots d'étranglement.
- Traitement initial : Le processus de collecte peut inclure un premier traitement des données (ETL - Extract, Transform and Load) pour faciliter leur exploitation ultérieure.
Sources de données
les principales sources de données dans les entreprises sont :
- Les activités numériques des individus : Les employés et les clients laissent des empreintes numériques lorsqu'ils :
- Naviguent sur le Web
- Effectuent des achats en ligne
- Utilisent le courrier électronique
- Interagissent avec les médias sociaux
- Les activités propres à l'entreprise : Les entreprises génèrent et collectent des données à travers :
- Leurs opérations commerciales
- La collecte et l'analyse de données pour leur usage interne
- Les machines (M2M) : Les dispositifs et systèmes automatisés échangent continuellement des données , notamment dans le contexte de l'Internet des Objets (IoT), les transactions et paiements, les photos et vidéos, etc...
Stockage et modélisation des données
Stockage des données
Cette phase garantit que les données collectées sont conservées de manière sûre et accessible, formant la base de toute exploitation future.
- Mise en place d'une interconnexion sécurisée depuis le Système d'Information (SI) vers un cloud privé certifié
- Chiffrement des données avant stockage
- Utilisation de différentes solutions de stockage :
- Datalake pour les données brutes non structurées
- Data warehouse pour les données transformées structurées
- Data lakehouse combinant les avantages des deux approches précédentes
Modélisation des données
La modélisation structure les données de manière logique et cohérente, facilitant leur compréhension et leur utilisation par les différents acteurs de l'entreprise.
- Consolidation des données hétérogènes issues de différentes sources
- Préparation des données pour alimenter les outils de datavisualisation, de datascience et les plateformes décisionnelles
- Prise en compte de la logique métier et du contexte pour modéliser les données brutes
- Assurance de la cohérence des conventions de nommage, des valeurs par défaut et de la sémantique
- Sécurisation des données, notamment par l'anonymisation ou la pseudonymisation
Transformation et analyse des données
Transformation des données
Cette étape convertit les données brutes en informations exploitables, les rendant prêtes pour l'analyse et la prise de décision.
- Nettoyage, mise à jour et structuration des données brutes
- Conversion dans un format exploitable pour la visualisation et l'analyse
- Différents types de traitements :
- Constructif (ajout, copie, réplication)
- Destructif (suppression de champs ou d'enregistrements)
- Esthétique (normalisation de valeurs)
- Structurel (renommage, déplacement ou combinaison de colonnes)
Analyse avancée des données
L'analyse avancée permet d'extraire des insights précieux des données, offrant une base solide pour la prise de décision stratégique et l'innovation.
- Exploration et visualisation des données
- Utilisation d'algorithmes de machine learning et d'intelligence artificielle
- Identification de modèles, tendances et signaux faibles
- Mise en place d'un environnement de Data Science (ex : JupyterLab déployé sur Kubernetes)
- Possibilité de mise à l'échelle des ressources (CPU, GPU) à la demande
Partage et Réutilisation des données (Data Reuse)
Le Data Reuse maximise la valeur des données collectées en les appliquant à de nouveaux contextes, favorisant ainsi l'innovation et l'efficacité opérationnelle.
- Création de modèles spécifiques pour de nouveaux usages à partir de données initialement collectées dans un autre but
- Définition et création de modèles de données adaptés
- Accompagnement des équipes dans la prise en main de ces nouveaux cas d'usage
- Création des API pour permettre le partage des données
Interopérabilité et standardisation
Cette phase assure que les données peuvent être facilement partagées et comprises entre différents systèmes, augmentant leur utilité et leur portée.
L'adoption de formats standardisés pour faciliter les échanges entre différents systèmes d'information, permettant de structurer :
- Informations sur les clients
- Données transactionnelles
- Informations financières et administratives