DataOps : réinventer la gestion des données avec agilité et efficacité
Nicolas Bacher, Data Engineer revient sur les concepts de l’approche DataOps, ses bénéfices, et sa mise oeuvre sur les projets des clients de Claranet.
L'ère des données
Il est aujourd'hui difficile d'ignorer l'omniprésence des données dans notre vie quotidienne, avec plus de 400 exaoctets générés chaque jour à l'échelle mondiale. Cet énorme flux d'informations, souvent désigné sous le terme de Big Data, oblige les entreprises à reconsidérer leurs systèmes et à s’adapter à cette nouvelle réalité.
Cependant, cette révolution des données soulève plusieurs interrogations importantes pour les entreprises :
- Comment assurer la fiabilité des données ?
- Comment maintenir des systèmes à jour et en maitriser les coûts ?
- Comment accélérer le déploiement des nouvelles plateformes ?
- Comment maitriser l'accès aux informations stratégiques ?
Ces questions sont cruciales car les réponses détermineront leur capacité à prendre des décisions éclairées, essentielles pour rester compétitives.
Le passage au Cloud est devenu indispensable pour gagner en agilité face au traitement des vastes volumes de données. Grâce aux services managés offerts par des fournisseurs tels qu'Azure, AWS et GCP, les entreprises peuvent mieux gérer cette masse d'informations croissante et se concentrer sur l'innovation. Toutefois, même avec le Cloud, les interrogations subsistent :
Comment dépasser les limites des méthodes traditionnelles de gestion des données, souvent lentes et sujettes aux erreurs, pour répondre aux besoins dynamiques des entreprises modernes ?
La révolution DataOps : agilité et efficacité
La DataOps, contraction de "Data Operations", redéfinit la manière dont les entreprises traitent leurs données. En s’inspirant des meilleures pratiques de collaboration, d’automatisation, et d’intégration continue du DevOps, la DataOps ne se contente pas d'accélérer les processus : elle réunit les équipes DevOps, les data scientists, et les data engineers pour instaurer une nouvelle agilité dans la construction des pipelines de données. Cette coordination, parfaitement alignée sur les besoins en constante évolution du marché, répond également à la complexité croissante des environnements de données modernes. Chaque étape, de la collecte des données à leur exploitation, est optimisée pour garantir rapidité, fiabilité, et flexibilité. Ce n’est plus simplement une gestion de workflows, mais une véritable orchestration fluide et adaptable.
Les piliers de la DataOps : une nouvelle approche dans la gestion des données
Par définition, la DataOps vise à améliorer la qualité et de réduire le temps de cycle de l'analyse des données. C’est pourquoi un des concepts clés qu’elle adopte est l’Infrastructure as Code (IaC), emprunté aux architectures cloud et à leurs pratiques de déploiement. En reprenant l’IaC, la DataOps apporte la même agilité et automatisation dans la gestion des données, permettant ainsi de définir et de gérer les infrastructures de données de manière déclarative. Cela facilite l’orchestration des processus de bout en bout, assurant une cohérence et une répétabilité pour les différents flux ETL et les déploiements.
Mais la force de la DataOps ne s’arrête pas là. Elle intègre un cycle de vie complet pour les données, qui couvre chaque étape essentielle du processus. Tout commence par la planification, où les équipes métiers collaborent pour définir les indicateurs clés de performance (KPI). Ensuite, vient la phase de développement, pendant laquelle ces indicateurs ou ces modèles de machine learning sont construits.
L'intégration est l’étape suivante : ils sont intégrés dans les stacks technologiques existantes. Une fois intégrés, ils sont soumis à des tests rigoureux pour s'assurer qu’ils respectent la logique métier et répondent aux critères opérationnels. Ces tests valident la conformité des données avant leur déploiement en production.
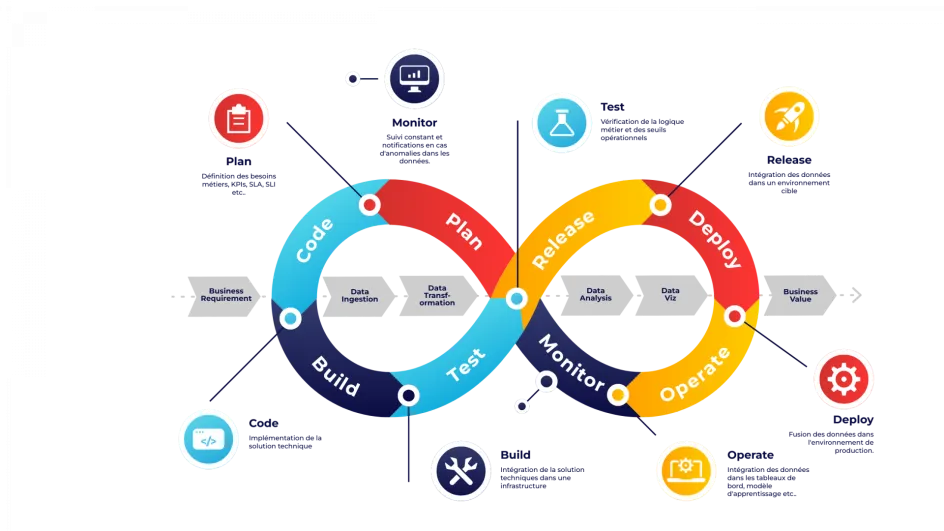
Les données passent ensuite dans une phase de “release”, où elles sont déployées dans un environnement de test, avant d’être mises en production dans la phase de déploiement. Une fois en production, les données sont exploitées au sein d’applications telles que des tableaux de bord Power BI ou Tableau, ou pour alimenter des modèles de machine learning.
Pour garantir la performance et la fiabilité de ces KPI produits, la surveillance continue et l’observabilité sont essentielles. Elles permettent de détecter les anomalies et d’optimiser les pipelines en temps réel, assurant ainsi une qualité irréprochable à chaque étape.
Finalement, ce qui rend la DataOps particulièrement puissante, c’est sa capacité à évoluer. Les principes tels que la modularité des pipelines, la sécurité, et l’automatisation font l'objet d'itérations continues pour s'adapter aux besoins changeants des entreprises et aux avancées technologiques.
La mise en œuvre de la DataOps chez Claranet : Innover pour mieux gérer les données
Chez Claranet, nous avons transformé la DataOps en une réalité concrète, en combinant innovation et efficacité pour redéfinir la gestion des données.
Infrastructure as Code (IaC) : Grâce à des outils comme Terraform, nos modules, notre solution maison "tfwrapper", disponible à la communauté, nous standardisons et simplifions la configuration des projets. Cela nous permet de déployer et de gérer des environnements complexes de manière agile, en réduisant les erreurs humaines et en centralisant les configurations. Résultat : une collaboration fluide entre les équipes et une traçabilité parfaite des modifications.
Automatisation des pipelines de données : Nos processus ETL sont entièrement automatisés, garantissant des flux de données rapides, fiables, et cohérents. Nous avons conçu des pipelines réutilisables et modulaires qui accélèrent le développement tout en assurant une cohérence entre les projets. Que ce soit pour le chargement de data lakes ou de data warehouses, chaque étape est orchestrée pour garantir une continuité opérationnelle mais également planifiée et capable de se relancer automatiquement en cas de besoin.
Chaîne CI/CD : L'intégration et le déploiement continu sont au cœur de notre stratégie DataOps. Nos pipelines CI/CD automatisent les tests et les déploiements. Cela réduit les erreurs et accélère les cycles de développement. Avec des templates développés pour différents cas d’usage, nous simplifions et standardisons les déploiements, rendant nos data engineers plus autonomes et efficaces.
Surveillance continue et gestion proactive : Notre infrastructure, basée sur une conception d’”Event Mesh”, fonctionne comme un système nerveux central, détectant et gérant les anomalies dans un environnement distribué. Il centralise les notifications, les alertes et les redirige vers les services d'alerte appropriés, tout en déclenchant automatiquement des tickets, que ce soit en réponse à une alerte ou de manière préventive. Chaque problème potentiel est ainsi identifié et résolu avant de devenir un incident majeur, garantissant des performances optimales et une continuité des opérations.
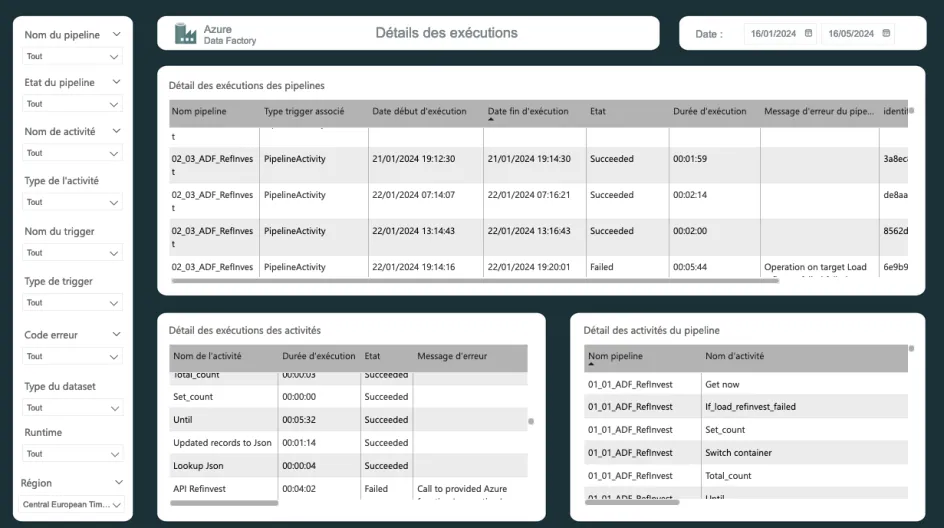
De plus, l'outil DataFlow Cockpit, développé par l’équipe Data Analytics, joue un rôle clé en offrant une vue d'ensemble et granulaire de chacun des pipelines de données. Grâce à ses tableaux de bord qui synthétisent l’ensemble des flux de données, nos clients peuvent visualiser leur environnement avec une grande précision, tout comme nos équipes. Ils peuvent ainsi suivre l’état de leurs systèmes de manière autonome.
Sécurité des données :Nous mettons en œuvre des pratiques de sécurité strictes, comme le chiffrement et une gestion précise des accès, pour protéger la confidentialité et l’intégrité des informations. Selon les besoins, nos infrastructures peuvent disposer de modules d’anonymisation et pseudonymisation pour répondre aux exigences du règlement général sur la protection des données (RGPD).
En combinant rigueur technique et innovation, nous offrons à nos clients une gestion des données à la fois robuste et sécurisée. Ils peuvent ainsi se concentrer sur l’exploitation maximale de leurs données, tout en minimisant les interruptions et les risques opérationnels.
L'optimisation du Run
Notre approche DataOps va au-delà de l'automatisation et de la surveillance proactive. Elle s'appuie sur les données collectées en production pour améliorer nos pipelines de données en continu. En examinant les performances réelles, nous repérons rapidement des moyens d'optimiser nos solutions pour les rendre plus efficaces et fiables.
Par exemple, en surveillant le fonctionnement de nos pipelines de données en production, nous les ajustons pour accroître leur stabilité et leur capacité à évoluer. Cela permet à nos systèmes de s'adapter naturellement aux besoins des clients tout en maintenant des performances élevées.
De plus, dès les phases de design, nous intégrons les exigences spécifiques de la production afin d'assurer que nos architectures de données soient optimisées en termes de qualité et de performance. Cela garantit non seulement une mise en œuvre fluide, mais permet aussi de réduire les ajustements nécessaires une fois en production.
Ainsi, nous nous assurons que nos solutions sont performantes dès leur mise en service et qu'elles le restent tout au long de leur cycle de vie.
Vers l'avenir : DataOps et l’intelligence artificielle
La DataOps et l'intelligence artificielle évoluent ensemble pour permettre aux entreprises d'exploiter leurs données de façon plus agile et intelligente. Prenons l'exemple d'Uber, qui utilise Michelangelo pour entraîner des modèles de machine learning sur des GPU distribués. Cela optimise ses opérations à grande échelle. Netflix, quant à lui, se sert de pipelines de données solides pour tester et déployer des modèles de recommandation personnalisée, ce qui booste l'engagement des utilisateurs. De son coté, Airbnb croise différentes sources de données pour affiner ses recommandations d'expériences, incitant plus d’utilisateurs à faire des réservations.
Ces exemples montrent clairement comment la combinaison de la culture de la DataOps et de l'IA aident les entreprises à conserver un avantage compétitif, en s'adaptant rapidement aux changements et en anticipant les tendances.
La DataOps est en perpétuelle évolution, et sans que l'on puisse prédire sa prochaine mutation, celle ci continuera de servir un objectif d'améliorer la fiabilité, la performance et l'agilité dans l'exploitation des données en production et développer les usages autour de celle ci.